前回AI Vtuberを作成し、入力したテキストに対し音声で返答する仕組みを実装しました。
今回は、AIと音声で会話する処理を作成してみます。
AIとの音声会話で必要なモノ
AIとの会話の流れは以下の通り
- 入力された音声をテキストに変換
- chatGPTでテキストに回答
- 回答テキストを音声に変換し出力
また事前にAIのキャラ設定やアバター画像を生成し、人間の顔画像が音声を口パクで発する形とします。
AIアバター生成
今回は2つのAIを生成します。
- AI中国語教師 (中国語音声対応)
- AI秘書 (日本語音声対応)
▼最近発表されたStable DiffusionのBRAV5モデルを試してみます。
まず、「AI中国語教師」の画像生成。
プロンプトに「hanfu, 1girl, face focus,blue background」を入力して漢服を着た女性を生成。

LoRA(追加学習データ)を使わず、簡単なプロンプトだけでここまでリアルに近い画像となります。
▼Stable DiffusionのModel、LoRAについて
▼各種表情を生成

次に「AI秘書」を生成。スーツを着た日本人女性で各種表情を生成

画像生成AI「Stable Diffusion」に関連したツールやモデルは日々新しいモノが発表されていて物凄い勢いで進化しています。
音声をテキストに変換
入力された音声からテキストに変換するのにブラウザの「WebSpeechAPI」を利用。
「WebSpeechAPI」は以下2つから構成されます。
- 音声→テキスト「SpeechRecognitionAPI」
- テキスト→音声「SpeechSynthesisAPI」
実装方法やサンプルプログラムコードは、以前のブログに記載しているのでそのままコピペ。
実行にはChromeブラウザを使ってGoogleの音声解析エンジンを利用することに。
テキストから音声を返答
AIのキャラ設定、chatGTPでの回答、回答テキストの音声変換は前回AI Vtuber作成時のものをそのまま流用。
テキスト→音声の「VOICEBOX API」は中国語には対応していません。
まずは日本語会話を行う「AI秘書(日本語音声対応)」を完成させます。
AIとの日本語音声会話
早速日本語会話を試してみます。構成は以下の通り。
- 音声→テキスト「WebSpeechAPI(SpeechRecognitionAPI)」
- テキスト→テキスト回答「miibo API→GPT-4」
- テキスト→音声「VOICEBOX API」
▼「中国旅行での注意点は?」


回答のテキスト+音声が返ってくるまで70秒以上・・。しかも、「分からない」との回答です
通信内容を確認するとmiibo AIPの応答待ちが大部分を締めています。遅すぎて全く使えません。
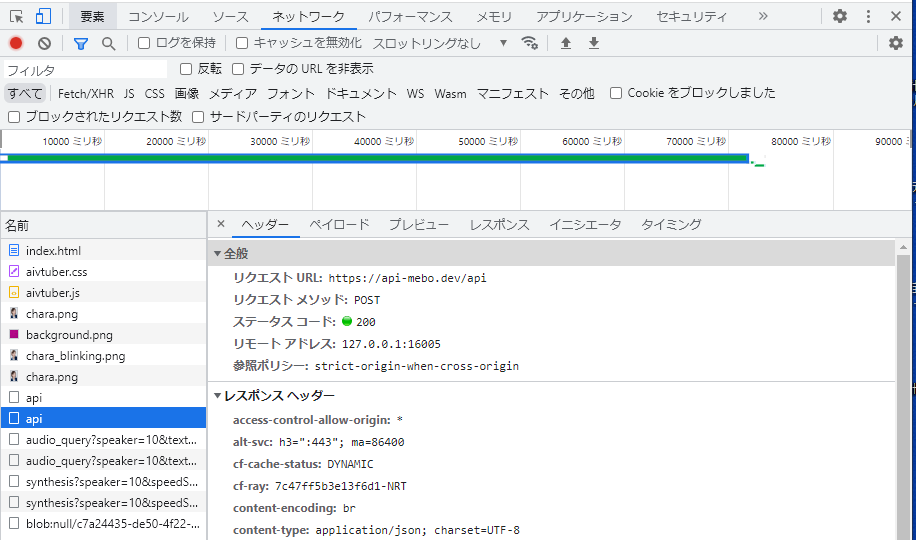
▼miiboから呼出す言語モデルを「GPT-4」から「GPT-3.5 turbo」に変更して再度試します。

「GPT-4」で回答出来なかった内容が旧バージョンの「GPT-3.5 turbo」では帰ってきました。応答時間も大分短くなり20秒ちょっと。
▼言語モデルを更に旧バージョンの「GPT-3 curie」に変更

20秒ほど待って「サーバーからの応答に時間がかかりすぎたため、処理を中断しました。」との回答です。
その後何度か試しましたが「GPT-4」の応答は早くても20秒はかかります。
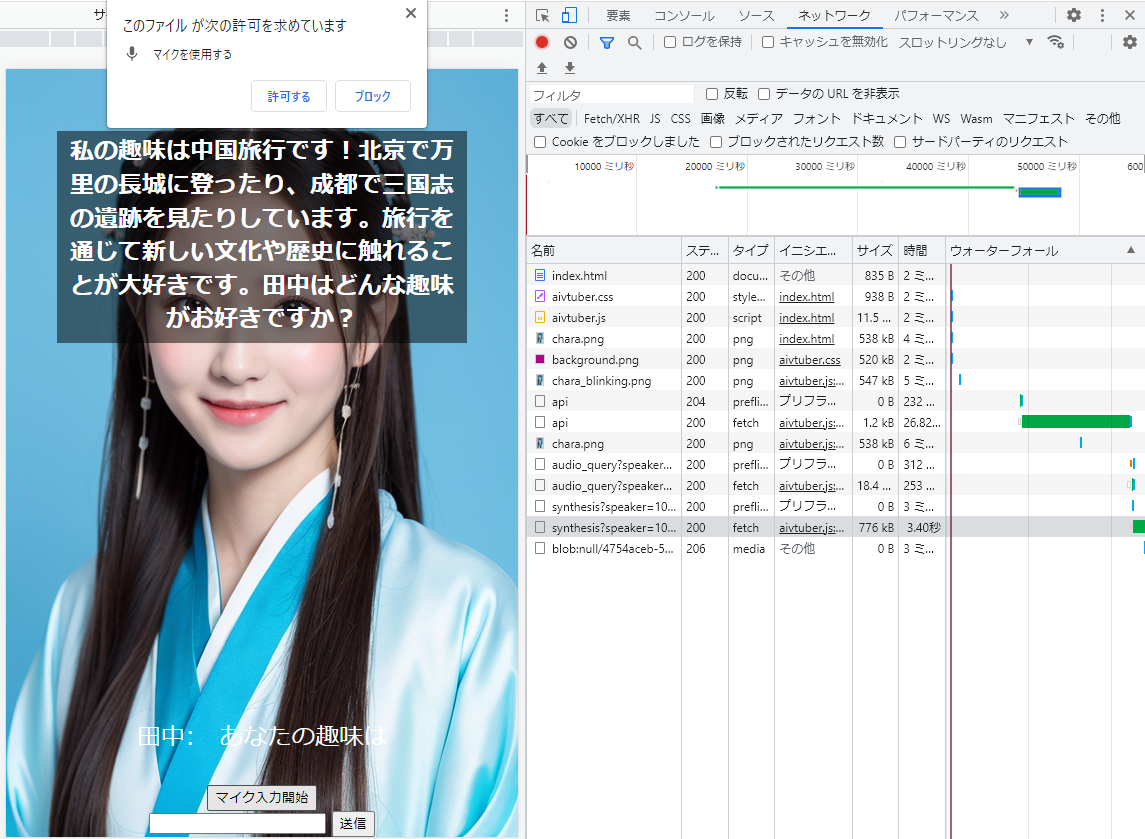
あと、ブラウザのセキュリティ設定を変えないと毎回マイク許可確認のダイアログが出てきます。
私のPC上で動作している「VOICEBOX API」のテキスト→音声変換は200文字で3秒程度。10年くらい前に購入した安物PCなので時間がかかっています。NVIDIAのGPU搭載PCで「エンジンモード:GPU」で処理すると大幅に早くなるかと思います。
まとめ
AIと音声会話する処理を実装しました。現状AIからの応答が遅すぎて全く実用レベルではありません。
今はchatGPT APIの呼出に日本の会社のサービス「miibo」を経由していますが、直接chatGPTを呼出せば速度はある程度早くなるかもしれません。
ただ、私は日本の携帯番号が無いのでOpenAI社のサービスが利用できない状況・・。
▼OpenAI社の各種サービスと利用価格
また、中国の大規模言語モデルAI「文心一言」等も申し込みしましたが、中国の身分証明書がないので利用できない状況です。