最近生成AIに興味があり色々試しています。
今回はAIボイスチェンジャー「RVC」の性能を検証してみます。
RVCとは
RVCとは、中国人が開発したAIボイスチェンジャーです。
他の音声変換AIと比較して以下の特徴があります。
- 学習に必要なデータが少ない(約10分の音声があればモデル生成可)
- 変換速度が非常に早い(リアルタイムでの変換可)
簡単に高性能なボイチェン音声を生成できるため、中国だけでなく日本でも使われて解説サイトも多くあります。
RVCリアルタイム変換検証
まずは、RVCリアルタイム変換を試してみます。
1.RVC学習済みモデルダウンロード
下記サイトで提供している学習済みモデルを使用。
【図解】超高性能AIボイスチェンジャー「RVC」のしくみ・コツ
RVC v2「ヒロインキャラ」をDLします。
2.VC Clientのダウンロード
リアルタイム音声変換を行うためのクライアントソフトウェア「VC Client」をDL。
GitHub - w-okada/voice-changer: リアルタイムボイスチェンジャー Realtime Voice Changer
このソフトは、RVCだけではなく他の音声変換AI(MMVC、so-vits-svc、DDSP-SVC)にも対応しています。
3.VC Clientの実行
「RVC」モードで起動し、ダウンロードした学習済みモデルを設定

「Start」を押し、マイク音声入力開始。ところが・・何も反応無し。
20秒以上経ってやっと応答が帰ってきました。私の声が別人の声に変換されてはいますが、途切れ途切れで品質が悪すぎです。
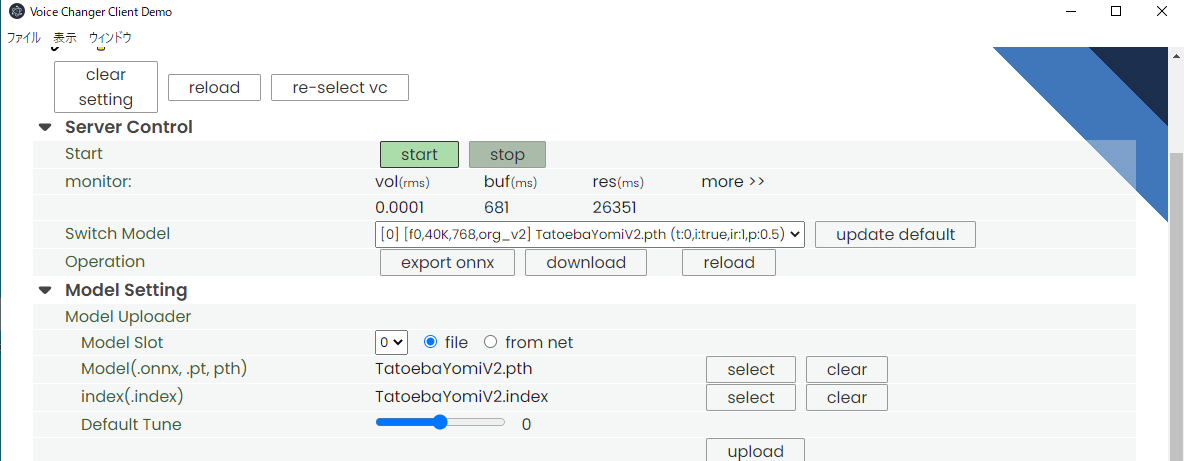
「VC Client」の説明を確認すると
GPU を使用するとほとんどタイムラグなく変換可能です。CPU でも最近のであればそれなりの速度で変換可能。古い CPU(i7-4770)だと、1000msec くらいかかってしまう。
との事です。私の使っているPCは10年くらい前に購入した安物なので、resが26351msec。動作させるのは無理でした。
RVCで歌わせてみた
最近、各動画投稿サイトではRVCを使った「歌ってみた」動画が流行っています。
今度はこの「歌ってみた」をRVCで生成。
例えば「岸田首相」にYOASOBIの「アイドル」を歌わせる場合は、以下の流れとなります。
- 「岸田首相」の音声を10分程度集めRVC学習
- 「アイドル」の音源からボーカル部分と演奏部分に分離
- 抽出したボーカル部分を学習済みRVCで推論。(ボイチェン)
- ボイチェン後のボーカルと演奏部を結合
ただ、著作権の問題があるので、今回は全てフリー素材を使用します。
1.フリー音楽をダウンロード
多くのYoutuberが使用しているフリー音楽の「シャイニングスター」をDL
シャイニングスター | 公式歌詞 & 音源無料ダウンロード 魔王魂
2.RVC学習済みモデルダウンロード
先程のリアルタイム変換でも使用した学習済みモデルをDL
【図解】超高性能AIボイスチェンジャー「RVC」のしくみ・コツ
→「ヒロインキャラ」「爽やかな青年」
3.RVC WebUI(音楽のボーカル、演奏分離)
Googleの無料機械学習環境「Colab」で動作するRVC WebUIを使用。
日本語に翻訳したWebUIもあるようですが、そのまま中国語のオリジナル版を使用。
また、今回はRVC学習はせず既に学習済みモデルを使用するので、下記処理はスキップ
- 挂载谷歌云盘
- 从谷歌云盘加载打包好的数据集到/content/dataset
- 重命名数据集中的重名文件
「启动web」でWebUIを起動。
「Accompaniment and vocal separation」タブでHP5モデルを使用して「シャイニングスター」音源のボーカル部と演奏部を分離します。

/content/Retrieval-based-Voice-Conversion-WebUI/opt に2ファイルが生成されました。
- ボーカル主旋律のみの音声「vocal_◯.wav」
- 演奏とハモリの音声「instrument_◯.wav」
どのように実現しているか不明ですが、主旋律のみが完全に抽出できています。
4.RVC WebUI(音楽のボーカルボイチェン)
「Model Inference」タブで先程分離したボーカル部をボイチェンします。
RVC学習済みモデル(.pthファイル)を下記パスに配置
- /content/Retrieval-based-Voice-Conversion-WebUI/weights/

学習済みモデルに「爽やかな青年」を選択。女性ボーカル→男性にボイチェンするので、Transposeに「-12」を設定しボイチェン音声を生成。
次に学習済みモデルに「ヒロインキャラ」を選択。女性ボーカル→女性にボイチェンするので、Transposeに「0」を設定し生成。
5.ボーカルと演奏の合成
動画編集ソフト「DaVinci Resolve」でボイチェンしたボーカルと演奏を合成。
完成したのは下記の通り
▼男性「爽やかな青年」に変換
▼女性「ヒロインキャラ」に変換
▼女性「ヒロインキャラ」に変換失敗?
音声分離を「HP5モデル」以外の別の方法で実行して、ボイチェンすると高音部がかすれ声になっています。「歌ってみた」を作るには、オリジナルの音源からボーカル部分のみを正確に抽出するのが大切なようです。
まとめ
AIボイスチェンジャー「RVC」を使って「リアルタイム変換」と「歌ってみた」を生成しました。
「リアルタイム変換」は私の使っているPCのスペックが低すぎて実行出来なかったですが、「Google Colab」環境でのボイチェンはなかなか高性能です。
中国でも今年一番流行った歌手は「AI孙燕姿」だ。という人も少なくないくらいAIに歌わせる動画が出てきています。