機械学習による翌月の商品売上予測~Kaggle「Predict Future Sales」
前回、pythonの機械学習環境を構築し、世界中のデータサイエンティストが集うプラットフォーム「Kaggle」でタイタニック号生存予測を投稿するまでを記載しました。
今回は、より実践的なテーマ「翌月の店舗商品別の売上数予測」について挑戦してみようと思います。
Predict Future Sales
今回使用したコンペは「Predict Future Sales」。
データ分析の入門として有名なタスクで、日本語で解説したサイトも多くあります。
概要
ロシア最大のソフトウェア会社「1C Company」から提供された店舗商品別の日次売上実績データ(33か月分)を使って、翌月の店舗商品別の売上数を予測します。予測する商品には訓練データに含まれていない新製品もあり、それをどのように予測するかが問われます。
使用するデータ
- sales_train.csv 2013/01~2015/10の店舗商品別の日次売上情報
- items.csv 商品情報
- item_categories.cs 商品のカテゴリ情報
- shop.csv 店舗情報
- test.csv 予測対象の店舗商品
予測手順
このタスクは既に多くの人が予測手順・プログラムを公開しています。まずは、その中でも評価が高いものを真似をするところから始めます。
参考にしたのはアルゴリズム「xgboost」を使用した下記です。
Feature engineering, xgboost | Kaggle
どのようにデータを加工し、特徴量を作成しているか等を理解します。
データ前処理
trainファイル
trainファイルには次のような形でデータが保存されています。(一部抜粋)
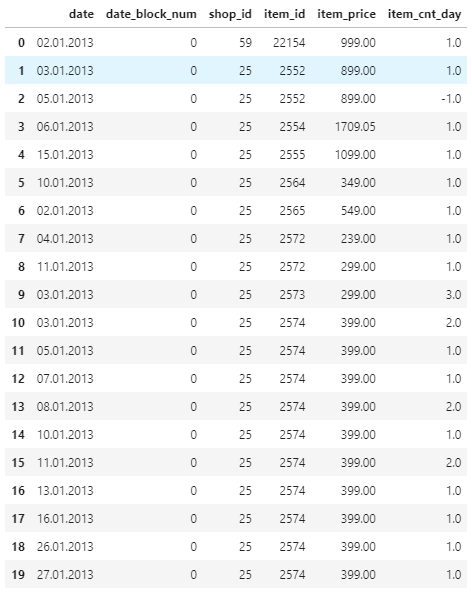
日付、店舗ID、商品ID、商品価格、販売数量とdate_block_num(2013/01を0とした月毎の連番)。データ件数は2,935,849件です。販売数量は返品があった場合マイナスになっているようです。
このファイルから、販売数量と商品価格の分布を表示します。
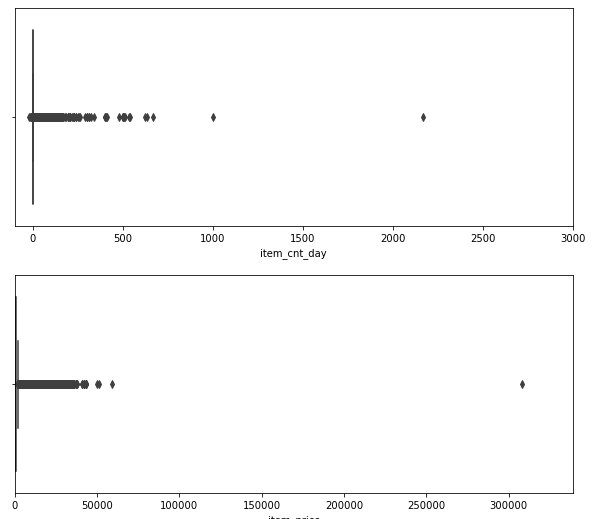
明らかに他の情報と異る外れ値があるので、これらのデータは使用せず削除することにします。
また、商品価格がマイナスとなっているデータも1件だけあります。これは登録ミスだと判断して同じ年月/店舗ID/商品IDの中央値で上書きします。
店舗ファイル
次に、店舗情報ファイルを確認します。(一部抜粋)
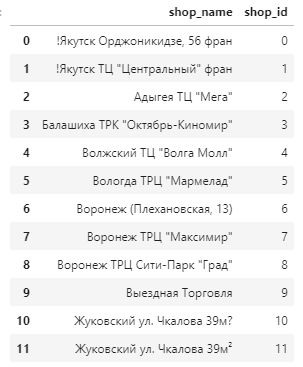
内容がロシア語なので判断が難しいですが、店舗ID:10と11は店舗名がほぼ同じで間違えて2重で登録されてしまったと考えられます。train、testファイル内の店舗ID:10を11に置き換えて、同一店舗として扱う事にします。
また、店舗名は都市名+" "+店舗名の形で登録されているようです。スペースで分解して都市と店舗名の項目に分けます。
カテゴリファイル
カテゴリファイルの内容は以下の通りです。(一部抜粋)
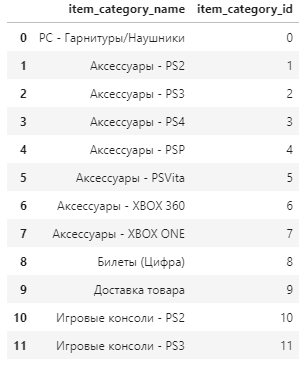
カテゴリ名には「-」区切りで大分類小分類のような形になっています。同じように分解してtypeとsubtypeに分けます。
月間売上高の集計
今回予測するのは翌月の店舗商品別の月間売上数予測です。trainファイルには日次の売上数が登録されているので、集計し月間売上実績数を求めます。集計する際に販売数×販売金額=売上金額情報も計算します。
ラグ特徴量の作成
月次商品販売数には周期性(12月は販売数が全体的に大きく増えるなど)がみられるのでラグ特徴量を作成します。1ヶ月前、2ヶ月前、3ヶ月前、6ヶ月前、12ヶ月前の販売数量を特徴量として追加します。
また、月毎商品毎・月毎店舗毎の平均販売個数とそのラグも追加します。
更に、月毎カテゴリー毎・月毎店舗毎カテゴリー毎・月毎店舗毎tyep毎・月毎店舗毎subtyep毎・月毎都市毎・月毎商品毎都市毎のそれぞれの平均販売個数を計算します。
特徴量の追加
追加の特徴量として以下を設定します。
- 直近6ヶ月の商品販売価格推移
- 先月の店舗の平均売上高
- 月の日数(1月は31、・・)
- 商品が最初に売れたのは何か月前か
- 商品が最後に売れたのは何か月後か
これらの情報を付与して、最終的に訓練データとして出来たのは下記の通りです。(一部抜粋)
| id | date_block_num | shop_id | item_id | item_cnt_month | city_code | item_category_id | type_code | subtype_code | item_cnt_month_lag_1 | item_cnt_month_lag_2 | item_cnt_month_lag_3 | item_cnt_month_lag_6 | item_cnt_month_lag_12 | date_avg_item_cnt_lag_1 | date_item_avg_item_cnt_lag_1 | date_item_avg_item_cnt_lag_2 | date_item_avg_item_cnt_lag_3 | date_item_avg_item_cnt_lag_6 | date_item_avg_item_cnt_lag_12 | date_shop_avg_item_cnt_lag_1 | date_shop_avg_item_cnt_lag_2 | date_shop_avg_item_cnt_lag_3 | date_shop_avg_item_cnt_lag_6 | date_shop_avg_item_cnt_lag_12 | date_cat_avg_item_cnt_lag_1 | date_shop_cat_avg_item_cnt_lag_1 | date_shop_type_avg_item_cnt_lag_1 | date_shop_subtype_avg_item_cnt_lag_1 | date_city_avg_item_cnt_lag_1 | date_item_city_avg_item_cnt_lag_1 | date_type_avg_item_cnt_lag_1 | date_subtype_avg_item_cnt_lag_1 | delta_price_lag | delta_revenue_lag_1 | month | days | item_shop_last_sale | item_last_sale | item_shop_first_sale | item_first_sale |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 11127994 | 34 | 45 | 3280 | 0 | 20 | 55 | 13 | 2 | 0 | 0 | 0 | 0 | 0 | 0.258545 | 0.02272 | 0.069763 | 0.071411 | 0.159058 | 0.180054 | 0.126709 | 0.128784 | 0.139038 | 0.137573 | 0.181274 | 0.196899 | 0.126831 | 0.089294 | 0.126831 | 0.135376 | 0 | 0.146973 | 0.196899 | 0.171143 | -0.290039 | 10 | 30 | 1 | -1 | 34 | 34 |
| 11127995 | 34 | 45 | 4393 | 0 | 20 | 22 | 5 | 14 | 0 | 0 | 0 | 0 | 0 | 0.258545 | 0.02272 | 0.023254 | 0.071411 | 0.113647 | 0.040009 | 0.126709 | 0.128784 | 0.139038 | 0.137573 | 0.181274 | 0.22876 | 0.133301 | 0.277344 | 0.135132 | 0.135376 | 0 | 0.494141 | 0.214355 | -0.597168 | -0.290039 | 10 | 30 | 1 | -1 | 19 | 19 |
| 11127996 | 34 | 45 | 4352 | 0 | 20 | 22 | 5 | 14 | 0 | 0 | 0 | 0 | 0 | 0.258545 | 0.045441 | 0.023254 | 0.238037 | 0.02272 | 0.280029 | 0.126709 | 0.128784 | 0.139038 | 0.137573 | 0.181274 | 0.22876 | 0.133301 | 0.277344 | 0.135132 | 0.135376 | 0 | 0.494141 | 0.214355 | -0.181519 | -0.290039 | 10 | 30 | 1 | -1 | 24 | 24 |
| 11127997 | 34 | 45 | 18049 | 0 | 20 | 70 | 14 | 57 | 0 | 0 | 0 | 1 | NaN | 0.258545 | 0.090881 | 0.232544 | 0.285645 | 1.227539 | NaN | 0.126709 | 0.128784 | 0.139038 | 0.137573 | NaN | 0.336426 | 0.139404 | 0.106201 | 0.139404 | 0.135376 | 0 | 0.237305 | 0.336426 | -0.079773 | -0.290039 | 10 | 30 | 1 | -1 | 8 | 8 |
| 11127998 | 34 | 45 | 18027 | 0 | 20 | 70 | 14 | 57 | 0 | 0 | 0 | NaN | NaN | 0.258545 | 0.068176 | 0.093018 | 0.214233 | NaN | NaN | 0.126709 | 0.128784 | 0.139038 | NaN | NaN | 0.336426 | 0.139404 | 0.106201 | 0.139404 | 0.135376 | 0 | 0.237305 | 0.336426 | -0.105957 | -0.290039 | 10 | 30 | -1 | -1 | 5 | 5 |
| 11127999 | 34 | 45 | 18454 | 0 | 20 | 55 | 13 | 2 | 1 | 0 | 0 | 0 | NaN | 0.258545 | 0.045441 | 0.023254 | 0.071411 | 0.59082 | NaN | 0.126709 | 0.128784 | 0.139038 | 0.137573 | NaN | 0.196899 | 0.126831 | 0.089294 | 0.126831 | 0.135376 | 0.5 | 0.146973 | 0.196899 | -0.475098 | -0.290039 | 10 | 30 | 1 | -1 | 11 | 11 |
| 11128000 | 34 | 45 | 16188 | 0 | 20 | 64 | 14 | 42 | 0 | 0 | NaN | NaN | NaN | 0.258545 | 0.02272 | 0.069763 | NaN | NaN | NaN | 0.126709 | 0.128784 | NaN | NaN | NaN | 0.155884 | 0.094482 | 0.106201 | 0.094482 | 0.135376 | 0 | 0.237305 | 0.155884 | 0.081116 | -0.290039 | 10 | 30 | -1 | -1 | 2 | 2 |
| 11128001 | 34 | 45 | 15757 | 0 | 20 | 55 | 13 | 2 | 0 | 0 | 0 | 0 | 0 | 0.258545 | 0.113647 | 0.069763 | 0.095215 | 0.25 | 0.180054 | 0.126709 | 0.128784 | 0.139038 | 0.137573 | 0.181274 | 0.196899 | 0.126831 | 0.089294 | 0.126831 | 0.135376 | 0 | 0.146973 | 0.196899 | 0.155884 | -0.290039 | 10 | 30 | 1 | -1 | 34 | 34 |
| 11128002 | 34 | 45 | 19648 | 0 | 20 | 40 | 11 | 4 | 0 | 0 | 0 | 0 | NaN | 0.258545 | 0.045441 | 0.069763 | 0.166626 | 0.090881 | NaN | 0.126709 | 0.128784 | 0.139038 | 0.137573 | NaN | 0.220825 | 0.08374 | 0.097046 | 0.08374 | 0.135376 | 0 | 0.224243 | 0.220825 | -0.091736 | -0.290039 | 10 | 30 | -1 | -1 | 11 | 11 |
| 11128003 | 34 | 45 | 969 | 0 | 20 | 37 | 11 | 1 | 0 | 0 | 0 | 0 | 0 | 0.258545 | 0.068176 | 0.116272 | 0.023804 | 0.068176 | 0.119995 | 0.126709 | 0.128784 | 0.139038 | 0.137573 | 0.181274 | 0.256836 | 0.128174 | 0.097046 | 0.126343 | 0.135376 | 0.5 | 0.224243 | 0.240967 | -0.605957 | -0.290039 | 10 | 30 | 1 | -1 | 17 | 17 |
1000万件を超えるデータとなり各集計処理に時間が結構かかりました。
xgboostで訓練・予測
作成した特徴量を元に機械学習を行います。今回使用したアルゴリズムは「xgboost」、ハイパーパラメータは下記の通りです。学習用として13~32か月目のデータを使用し33か月目が訓練データです。※最初の12か月分はラグ情報(12か月前の販売数など)が無いので学習データとしては使用しません。
model = XGBRegressor(
max_depth=8,
n_estimators=1000,
min_child_weight=300,
colsample_bytree=0.8,
subsample=0.8,
eta=0.3,
seed=42)最後に34か月目のテストデータを予測して終了です。Kaggleに投稿するとスコアが「0.91338」で3131位/12202でした。平均二乗偏差(RMSE)によって評価されスコア値が小さいほど予測の精度が高いことを表します。1位のスコアは「0.75368」なのでまだ改善の余地がありそうです。
今回の学習で重要だった特徴量は下図の通りです。
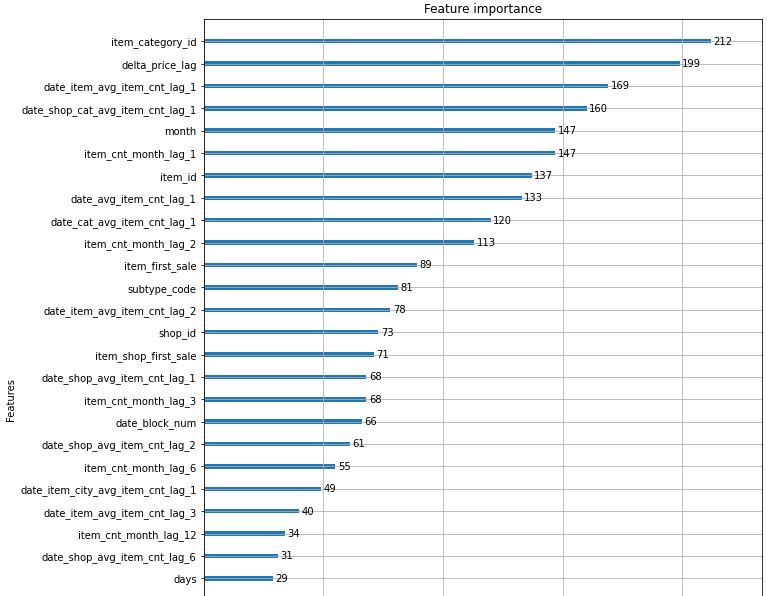
参照したサイトと同じ手順で特徴量の作成・機械学習を行ったのに、この結果は何故か大きく異なっていました。
まとめ
機械学習を使った商品売上予測を試してみました。今回の内容はKaggle「Predict Future Sales」の公開されているソースコードをそのまま真似したものです。途中の説明は大分端折っているので、詳しく知りたい場合は参照元URLを参考にしてみてください。
この内容は3年前に投稿されたものです。最新の方法やこれ以上精度を上げる方法が無いか次回以降考えてみます。